[Edit: I now have a follow-up post that adapts this analysis to real-world constraints!]
As we continue our worldwide fight with the coronavirus, many countries are looking to gradually transition away from strict lockdowns and toward effective test-and-trace programs. The idea is that if we can test people on a mass scale and track down and quarantine the contacts of anyone who tests positive, we can keep the virus from spreading even as our lives go back halfway to normal.
South Korea has had luck with this approach, but they had a substantial advantage over the West: they acted quickly and never let the virus become widespread. This means that they could keep the virus under control while testing only 20 thousand people per day. On the other hand, the United States would need to test millions of people per day (35 million per one estimate) to have an effective test-and-trace program. The problem is, we are nowhere close to having such a testing capacity; currently the U.S. tests a few hundred thousand people daily.
.
Yesterday I stumbled upon a New York Times article about Germany’s (relative) success fighting COVID-19. One paragraph jumped out at me:
Medical staff, at particular risk of contracting and spreading the virus, are regularly tested. To streamline the procedure, some hospitals have started doing block tests, using the swabs of 10 employees, and following up with individual tests only if there is a positive result.
If you don’t have enough tests, this is a great idea! Say that 1% of medical employees have the virus. You want to test the 100 employees at your hospital, but don’t have 100 tests. So you collect samples from everyone and put them into batches of ten samples each. You mix the samples in each batch and test each batch; the test comes back positive only if someone in the batch has the virus. At this point most of the employees are in the clear, but some batches (one, on average) comes up positive. You follow up by testing everyone in that batch individually. All in all, this only uses 20 tests on average, compared to the 100 tests you would have had to use to test everyone individually!
The biggest problem I see with this approach is that it takes several days to process a test, and you’d rather not wait for two rounds of tests before knowing who’s positive. But there’s a clever way you can get around that, still using only 20 tests but doing the tests all at once! The trick is to put your 100 employees into a 10 by 10 square, make batches out of each “row” and “column”, and test these 20 batches.
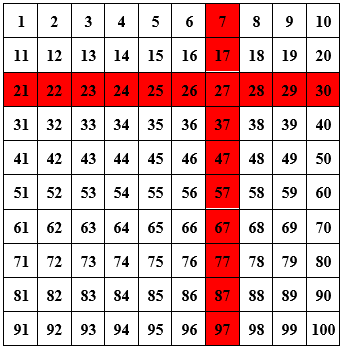
Say that the batch test of employees 21 through 30 comes back positive, as does the test of employees 7, 17, …, 97, and all other tests come back negative. Then you’ve figured out who’s positive: employee 27.1
.
The problem with applying this idea directly to test-and-trace is that the “test” part is on a much more massive scale. Putting people into a square and testing each row and column works if you have 100 people. But if you do that with 1 million people, then you’d be mixing samples of 1,000 people. While combining and testing ten samples works well, it’s unclear that a test would be sensitive enough to detect a positive if it’s diluted a thousand-fold. (I don’t know — maybe it could! Perhaps someone who studies this could weigh in in the comments!) More importantly, though, even if you could detect a positive in a mix of 1,000 samples, if you have a 1% positive rate then nearly every block test will come back positive, and you will have learned nothing.
That said, the same basic idea — grouping samples into batches so that each person’s sample is in multiple batches, and highlighting a person as “positive” if every batch they’re in turns up positive — can still work, and (in theory at least) works surprisingly well! I’m not the first to think of this; a recent paper by Shental et al. proposes the exact same idea:
We developed P-BEST – a method for Pooling-Based Efficient SARS-CoV-2 Testing, using a non-adaptive group-testing approach, which significantly reduces the number of tests required to identify all positive subjects within a large set of samples. Instead of testing each sample separately, samples are pooled into groups and each pool is tested for SARS-CoV-2 using the standard clinically approved PCR-based diagnostic assay. Each sample is part of multiple pools, using a combinatorial pooling strategy based on compressed sensing designed for maximizing the ability to identify all positive individuals.
They tested their approach in practice, and it worked!
We evaluated P-BEST using leftover samples that were previously clinically tested for COVID-19. In our current proof-of-concept study we pooled 384 patient samples into 48 pools providing an 8-fold increase in testing efficiency. Five sets of 384 samples, containing 1-5 positive carriers were screened and all positive carriers in each set were correctly identified.
Later in the paper, the authors specify that their 48 batches each had 48 samples, meaning that each sample was included in 6 batches. Let’s spell out this approach to testing. The procedure is as follows:
(1) Acquire a sample from every person you wish to test.
(2) Divide your samples randomly into equal-sized batches (Shental et al. chose a batch size of 48). Within each batch, take a portion of each sample, and mix these together.
(3) Repeat step 2 several times, so that each sample is included in multiple batches. (Shental et al. chose to do step (2) six times.)
(4) Test every batch. Count a test subject as positive if every batch that their sample was included in came back positive. Otherwise count them as negative.
If your tests don’t have false negatives, then you’ll detect every single positive case: after all, if you have the virus then every batch your sample was included in will come back positive. However, this procedure may yield false positives: someone could get unlucky, if every batch their sample is included in also contains a sample of someone with the virus.
How can you reduce the false positive rate if you want to use the batch testing method? One way is to increase the number of tests you use, so each sample can be included in more batches. But let’s say you have a limited number of tests. The other parameter you can change is the size of your batches.
How big should you make your batches? Let’s take a look at the chart below, which shows the false positive rate that is achieved with the batch testing method, as a function of (1) the number of tests per capita available to us and (2) the size of the batches, assuming that 1% of the population being tested has the virus. (I talk about the math I used to find these values toward the end of this post.)
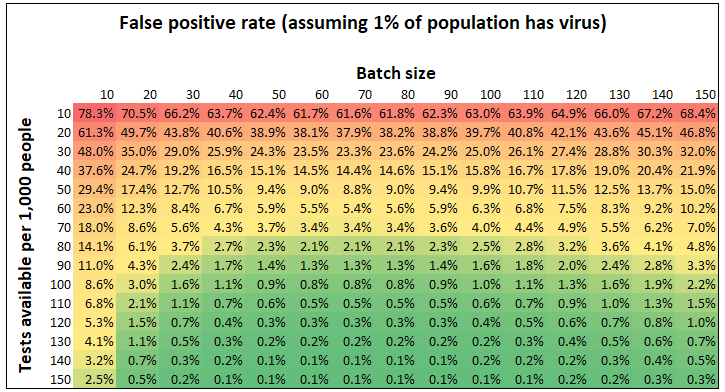
What immediately jumps out is the obvious thing: the more tests you have available, the lower your false positive rate. But what’s more intriguing is that the same batch size — around 70 — is optimal, no matter how many tests you have available to you. This is not a coincidence. In general, if x% of your population has the virus, the optimal batch size is around 70/x. For example, if you 1% of your population has the virus, the optimal batch size is roughly 70; if 2% have the virus, then the optimal batch size is 35. (I show the derivation of this fact — including where the 70 comes from — toward the end of the post.)
Both of these facts are important, but here’s an even more fundamental fact: These false positive rates are really low! If you have just 100 tests available for every 1,000 people you want to test, you can test everyone using the batch testing method and your false positive rate will be below 1 percent.
So suppose your batch in the optimal way: 70/x people per batch, if you’re expecting x% of the population have the virus. As a function of (1) how many tests you have available and (2) the percent of people who have the virus, what false positive rate does the batch testing method get you?
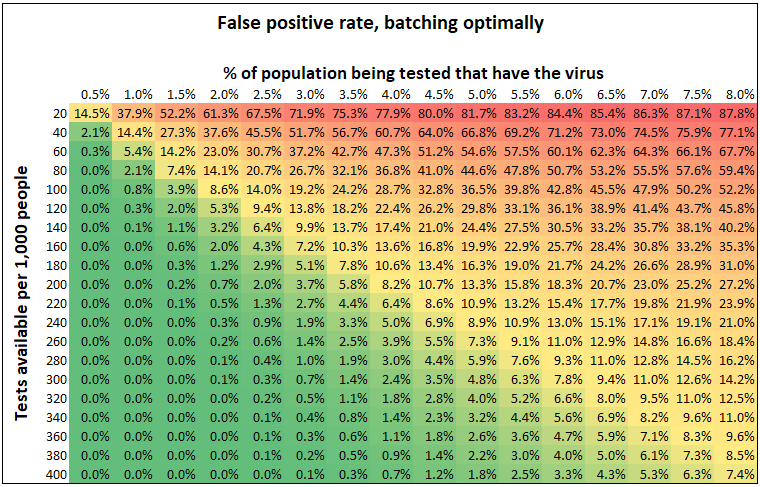
We’ve already seen that the more tests you have, the lower your false positive rate. It also makes sense that the more prevalent the virus is, the higher your false positive rate. That’s because the more prevalent the virus, the smaller you need to make the batches, but that means that each sample is included in fewer batches. As a result, if you have 200 tests per thousand people you want to test, you can get a 0.7% false positive rate if 2% of the subjects have the virus, but only an 8.2% false positive rate if 4% of them do.
Here’s a chart that summarizes this same numbers in a different way. Let’s say you know the prevalence of the virus and want to aim for a specific false positive rate. How many tests do you need?
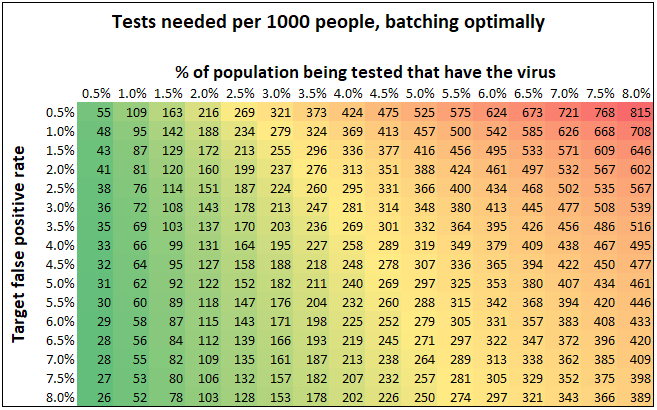
This is an interesting perspective as well: for instance, if you want to aim for a 3% false positive rate, you need just 143 tests per thousand subjects if 2% have the virus, compared to 348 tests per thousand if 5% have the virus.
But let’s not lose sight of the bigger picture: the batch testing method allows us to substantially reduce the number of tests we use while still keeping the false positive rate low. Of course, there are numerous caveats. Will the logistics of mixing tests be feasible to implement? How does this method fare if the tests themselves don’t have perfect specificity and sensitivity? Does the sensitivity of the tests available to us degrade substantially if we mix 70 tests together? These are all questions that have bearing on the analysis. But the fact is, Shental et al. have demonstrated that this approach is empirically feasible, and the parameters used (batch size, number of batches each sample is included in) matter a lot! For this reason, I hope that researchers trying to implement batch testing will find these thoughts useful.
***
The math:
Let’s say your population has n people, p fraction of which have the virus. You might not know p exactly, but hopefully you have a decent guess. You have t tests available to you, and you want to test people in batches. What batch size should you use?
It makes sense to choose your batch sizes in such a way that the fraction of batches that come up positive isn’t near zero (in that case you’d be wasting tests by making batches too small) and isn’t near one (in that case you’d need to use lots and lots of tests to have a low false positive rate). The way to do this is to make your batch size inversely proportional to the fraction of people with the virus. So let’s say you want your batches to have size c/p for some constant c that you get to choose; this means that the average batch will contain c people who have the virus. Then each sample will be included in ct/(pn) batches. That’s because t total batches are tested, each of which has c/p samples, and there are n total samples. We ask: what is the false positive rate? That is, pick any subject who doesn’t have the virus. In terms of c, p, t, and n, how likely is it that every batch that subject is included in comes up positive?
Well, any batch with that subject’s sample contains c/p – 1 other samples. Since these samples are selected randomly from the population, the probability that none of them have the virus is roughly

The probability that the batch comes up positive is the probability that at least one person in the batch has the virus, i.e. 1 minus the above expression. This means that the false positive rate — the probability that every batch the person is in comes up positive — is

We ask: which c minimizes this expression? As you can verify by taking the derivative, the answer turns out to be roughly 

In conclusion, from a theoretical standpoint it makes sense to choose your batch sizes so that on average 0.7 people per batch have the virus. This conclusion doesn’t depend on the number of tests you have; the advantage of having more tests, though, is that you can include each sample in more batches (though, as discussed above, this has diminishing returns around the point where a sample is included in seven batches).
[See here for a follow-up post.]
.
1. If two employees are positive, you’d probably see two rows and two columns come back positive and then you’d have four suspected positives; that’s still better than just testing in batches of 10, because you’d have 20 suspects at the same point!↩
2. You can check this by multiplying the number of batches you test (i.e. 10 times the number of positive cases) by the number of people in each batch (0.7/p), and divide it by the number of people.↩
3. A note to theoretical computer scientists: choosing 




Interesting read. Given that your charts cap at 8%, is it safe to assume that batch testing only works for low prevalence rates? That is, if the prevalence percentage gets too high then you’d have to be content either with a high false-positive rate or administering a large number of tests. Thanks for sharing!
LikeLike
Batch testing definitely works much better for low prevalence rates. It can work for higher prevalence rates, but it either doesn’t save you much relative to just testing everyone, or you have to accept a high false positive rate.
I’ve extended the tables to 12%, if you’re interested:
(You may be wondering why second chart contains numbers larger than 1,000 tests per 1,000 people. That basically just means that for the given prevalence and target false positive rate, batch testing doesn’t buy you anything — you might as well just test everyone.)
LikeLike
I think you made some incorrect assumptions.
Making larger batches is much more expensive. The time it takes to mix and prepare would grow. The logistics of record keeping on large batchs as well. I think you need a cost function that grows with batch size.
LikeLike
Do you work on Covid testing? If so, I’m happy to defer. But if not, my intuition is that the cost of making large batches pales in comparison with the benefits incurred by reducing the number of tests you need to do. As for the logistics, there’s certainly a jump from individual tests to batch testing — I’m hoping that this can be overcome. But I don’t really have the intuition that keeping track of large batches is a lot harder than keeping track of smaller ones.
LikeLike